In risk and compliance work, customer identity verification is less about collecting a document and more about reaching a defensible conclusion: do I have enough evidence to trust who this person or business says they are? That question sits at the center of fraud prevention, AML controls, and account-opening decisions in the United States. In this article I break down the U.S. compliance baseline, the workflow I would use, the methods that actually hold up under audit, and the mistakes that create avoidable risk.
What matters most before you build a verification program
- The real goal is a reasonable, risk-based belief, not perfect certainty.
- Covered U.S. institutions need written procedures, recordkeeping, and ongoing monitoring, not a one-time check.
- Entity accounts require an extra layer because the legal entity is not the same thing as the people behind it.
- The strongest programs combine documentary and non-documentary checks, then escalate edge cases to human review.
- False positives and false negatives are both compliance issues, because they affect fraud, access, and audit defensibility.
What the process is really trying to solve
At a practical level, identity verification has two jobs. First, it reduces the chance that a fraudster, mule, or synthetic identity gets through the door. Second, it gives the business a defensible record that it acted on a risk-based standard instead of guessing. I prefer that framing because it keeps the team honest: the goal is not to prove a person’s identity with mathematical certainty, but to gather enough reliable evidence to support a sound decision.
That distinction matters. A weak process may be fast, but it creates downstream problems: account takeover, chargebacks, money movement abuse, exam findings, and a long tail of remediation work. A rigid process can be equally bad if it rejects legitimate customers with thin files, nontraditional documents, or complex business structures. The best programs are designed to manage both sides of that tradeoff at once.
Once you think in those terms, the rest of the design becomes clearer: define the proof standard, match it to risk, and keep enough evidence to explain the decision later. That standard becomes easier to defend once you anchor it to the actual U.S. rule set.
The U.S. compliance baseline I would build against
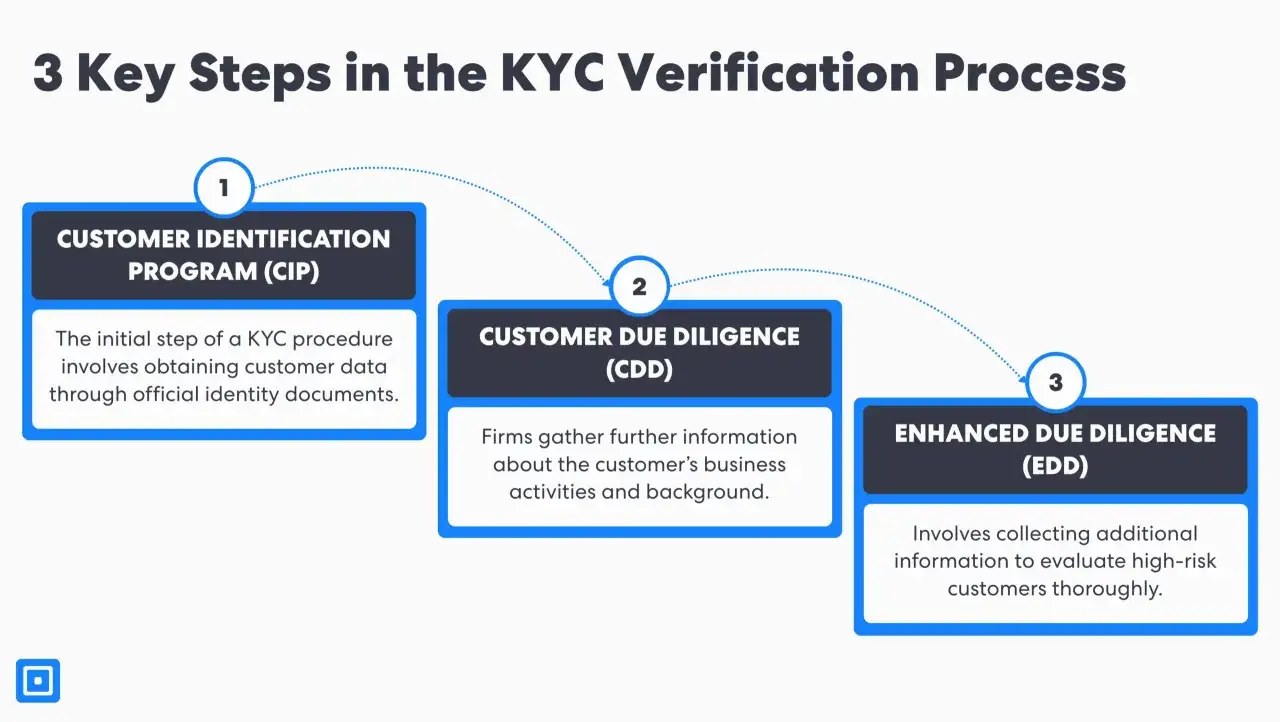
In the United States, the exact obligation depends on the institution and product, but the compliance logic is consistent. For covered financial institutions, the federal framework expects written procedures that identify and verify customers, understand the nature of the relationship, and support ongoing monitoring. I would treat that as the floor, not the finish line.
| Rule area | What it expects | Operational meaning |
|---|---|---|
| Customer identification | Collect identifying information before opening the account | Do not let onboarding outrun identity capture |
| Identity verification | Use documentary, non-documentary, or hybrid methods to form a reasonable belief | One method is rarely enough for every risk tier |
| Beneficial ownership | Identify and verify the natural persons behind legal entity customers | Entity documents alone do not tell you who is really in control |
| Ongoing monitoring | Update information and detect suspicious activity on a risk basis | Verification is a lifecycle control, not a one-time gate |
| Record retention | Keep the identifying and verification record set for a defined period | In banking CIP contexts, that window is commonly 5 years after account closure |
Two details are easy to miss. First, the rule set is explicitly risk-based, which means the evidence standard can rise or fall with product type, channel, geography, and customer profile. Second, the recordkeeping piece is not optional fluff; it is what makes the program auditable. Without a clean trail, a good decision can still look weak in an exam.
With the baseline in view, the next question is how far the requirement reaches when the customer is a company rather than a person.
Business customers need a separate verification path
When I review onboarding for legal entities, I never treat the entity name as the end of the story. A company can be real and still be a poor risk if the people behind it are opaque, nominee-controlled, or inconsistent with the stated activity. That is why entity onboarding should separate three layers: the legal entity itself, the people who own or control it, and the people who are authorized to act on it.
- Legal entity evidence shows the business exists and is structured as claimed.
- Beneficial owner evidence identifies the natural persons who own or profit from the entity.
- Controller or signer evidence shows who can actually move the account or submit instructions.
This separation is not academic. An LLC with clean formation documents can still be a shell. A partnership can have legitimate paperwork and still hide a bad actor through layered ownership. A sole proprietorship can be simple on paper and still require additional verification because the business and the individual are effectively the same risk surface. In practice, I see the strongest programs ask different questions for each structure instead of trying to force every customer into one template.
Once the customer type is clear, the process should move in a predictable sequence, not an improvised one.
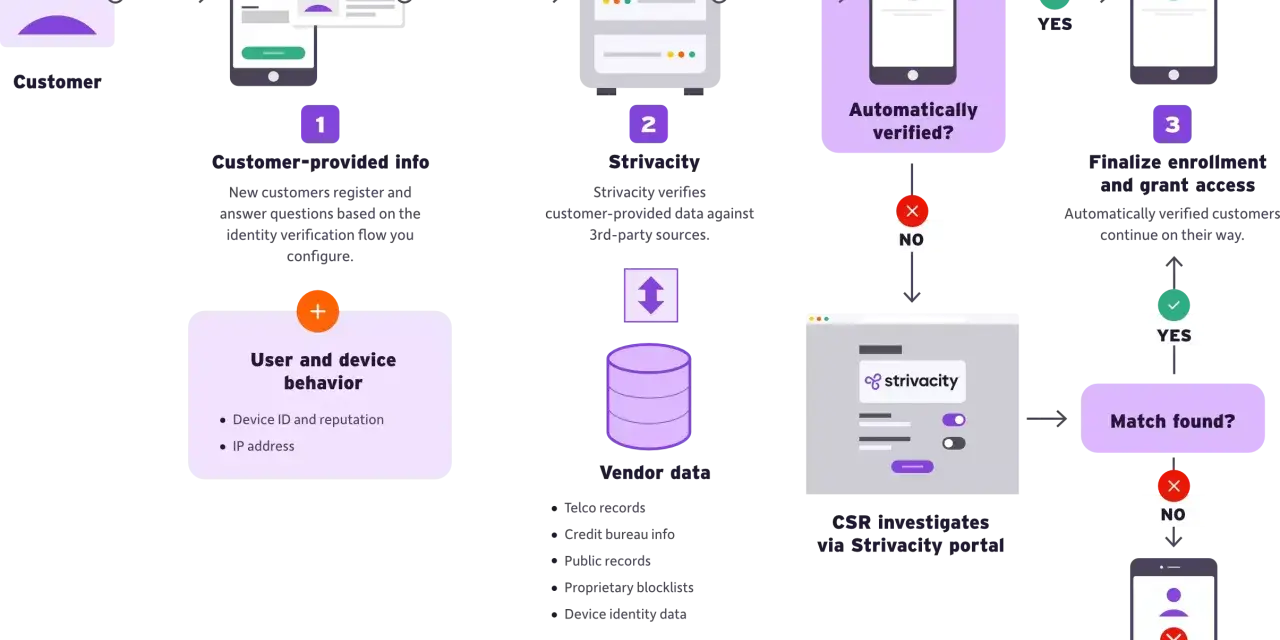
The workflow I would use from intake to approval
I like a workflow that is boring in the best possible way: consistent, explainable, and hard to game. The more exception-driven the process becomes, the more room it creates for error. A clean design usually follows the same six steps.
- Collect core data such as name, date of birth, address, tax identification information, entity details, and control information where relevant.
- Validate the fields for completeness, format, internal consistency, and obvious mismatches.
- Check the evidence using documentary inputs, data-source checks, device signals, or a blend of all three.
- Score the risk using customer type, geography, transaction intent, channel, and fraud history.
- Escalate edge cases to manual review when the evidence is thin, contradictory, or high-risk.
- Record the decision with the evidence used, the rule applied, and the date and time of the outcome.
The part most teams underinvest in is step 5. Manual review is not a failure of automation; it is the control that prevents automation from becoming brittle. I would rather slow down a small slice of high-risk accounts than let a large volume of ambiguous ones drift through on weak logic. That is especially true for remote onboarding, where fraud patterns evolve faster than static policy language.
The choice of method depends on risk, channel, and the level of assurance you need.
Which methods are worth combining in practice
There is no universal best method. The right answer depends on whether the customer is a consumer or an entity, whether onboarding is in person or remote, and how much friction the business can tolerate. I usually think about the options as a stack rather than a menu.
| Method | Strengths | Limits | Best use case |
|---|---|---|---|
| Documentary checks | Simple, familiar, and easy to explain | Forged or stolen documents can fool weak controls | Low to medium risk, especially when paired with another signal |
| Non-documentary checks | Scalable and useful when documents are unavailable | Thin-file customers and data mismatches can create false rejects | Broad consumer onboarding and step-up verification |
| Digital identity proofing | Strong for remote onboarding and repeatable at scale | Privacy, bias, and fallback design need careful governance | Digital-first products with meaningful fraud exposure |
| Manual review | Good at resolving nuance and exceptions | Slower and more expensive than automation | High-risk, unusual, or contradictory cases |
I find the current NIST digital identity framework useful here because it treats proofing as a risk-tiered exercise, not a single yes-or-no test. That is the right mindset for modern onboarding. If you need more assurance, raise the bar. If the customer and product are low risk, reduce friction without lowering the standard. The point is alignment, not uniformity.
Even a strong method fails if the operating controls are weak.
Controls and failure points that decide whether the program holds up
The most effective programs are not the ones with the fanciest vendor stack. They are the ones with disciplined governance. I would build around five control habits:
- Write the policy first so reviewers know when to accept, pause, escalate, or reject.
- Track exceptions so a special case does not quietly become the standard.
- Review performance metrics such as false accept rate, false reject rate, manual review volume, and average review time.
- Train reviewers on document types, fraud indicators, and escalation rules.
- Audit vendor outputs so outsourced checks do not become a blind spot.
The failure points are usually predictable. Name-only matching is too brittle. One-document-only logic is too easy to defeat. Treating every customer as low risk is lazy. Ignoring account changes after onboarding turns a one-time control into a stale record. And over-automating high-risk cases is a common way to produce both fraud losses and customer complaints.
I take that seriously because identity abuse is not a theoretical issue. FinCEN’s analysis of identity-related suspicious activity linked roughly 1.6 million reports, or 42% of the reports reviewed for that period, to about $212 billion in suspicious activity. That is a clear signal that weak identity controls create measurable financial and regulatory exposure, not just technical noise.
That leads to the operating model I would actually ship in 2026.
The operating model I would ship in 2026
If I were designing this for a U.S. business today, I would keep the model simple enough to run and strict enough to defend. My default would be a tiered hybrid process:
- Low-risk consumers get fast automated checks with a fallback if the data is incomplete.
- Medium-risk applicants get step-up proofing, such as a second data source or a human review trigger.
- High-risk accounts and legal entities get deeper beneficial owner review, enhanced due diligence, and tighter exception control.
- Reverification triggers include material profile changes, ownership changes, unusual access patterns, and high-risk transactions.
- Governance metrics are reviewed monthly so the process improves instead of drifting.
The version I would not ship is the one that chases speed at the expense of explainability. That model looks efficient until it has to survive a fraud wave, a regulator question, or a customer complaint about a wrongful rejection. The better design is one that gives the business a clear answer, the reviewer a clear rule, and the auditor a clear trail. If you keep those three things aligned, identity verification becomes a control that supports growth instead of slowing it down.